

2017 Sitecore Symposium
Like most folks in our space, I've been following the growing hype around the use of machine learning & artificial intelligence to drive customer experience. At last year's Sitecore Symposium, Todd Mitchell and Niels Kühnel highlighted a practical example of using machine learning to drive experiences in Sitecore via xConnect. Inspired, I started researching machine learning fundamentals, taking some Python classes and thinking through some possible use cases. A couple of months ago a use case surfaced -- a membership retention model to predict membership growth rates.
Project context
Our project goal was to build a model to forecast association membership for the upcoming year. We looked at the data we had to work with from legacy systems and made some guesses at what information (machine learning features) we might be able to pull out of that data. Our first objective was to develop a better, data-based estimate that could be used for annual budgeting -- something better than a gut feel estimate that comes from intuition and small samples of anecdotal membership information. Our second objective was to figure out how to use that information to better message the members. Now - on to the project.
Building my first model
Data wrangling
I estimate that I spent about 75% of the project time wrangling the data into a shape that could be used to build the model.
The source data included member information, member registration information, financial information, club information and competition information. All-in-all, there were 7 data sources and about 1.2 million records to work with. So, we’re not talking about big data, but it’s also a little beyond what you can work with in excel.
One of several blending & cleansing processes in RapidMiner
Most of the data was in a custom PHP membership management application. The first step was to build a handful of MySQL scripts to export the data into flat files. I described what I needed and had one of our teammates build the scripts. I used RapidMiner to do the bulk of the data manipulation. RapidMiner calls it blending & cleansing. There were over 100 separate data manipulation functions; from joining tables, to changing field types, to computing things like age from date of birth, to filtering out missing & bad data.
There were a couple of more complicated functions that I used custom Python to perform.
- I wanted to see if each registration was a member renewal or a new member registration. The process looped through each member registration year, looking back a year to do that.
- Then I wanted to look ahead a year (into the future) to see if the member renewed the following year. Again, the process looped through each member registration year, looking forward a year to do that. This piece of data ended up being what our model was built to predict (the Label that was used in the ML model).
A note about Python -- By “me”, I mean, I described what I needed done and had a Python developer build the script. Then I ran it in a Jupyter notebook. The first script took 4 ½ hours to run on my trusty 13” MacBook Pro. I could have run it in the cloud, but I hadn’t gotten there yet. I should also note that RapidMiner can perform functions like these. I just hadn’t gotten to the looping section of RapidMiner yet.
I probably did the whole blending & cleansing part of the project 5 different times. Each time I was able to use fewer steps, my data would get cleaner and the process would be easier to follow. Just like rookie software developers can write sloppy code, rookie data science practitioners can build sloppy models and sloppy model inputs. I hope to look back at my current work in a year and be embarrassed by it.
The output of blending & cleansing work was a flat table of about 350,000 rows that included the member’s gender, age range, club chapter, club type, competition level, whether they’ve donated and whether they subscribe to the magazine. Those were the inputs. The label (the thing we’re modeling for) was whether they renewed the following year.
Model building
Once I had the data cleaned it was time to build, train and evaluate the model. I used the RapidMiner Auto Model feature to do this. Based on the data structure, RapidMiner could tell that I had a regression analysis problem. That is, the need to predict the likelihood of a member renewing based on the evaluation of a number of different variables. RapidMiner took my dataset and built me the following models.
- Generalized Linear Model (GLM)
- Logistic Regression
- Deep Learning
- Decision Tree
- Random Forest
- Gradient Boosted Trees (XGBoost)
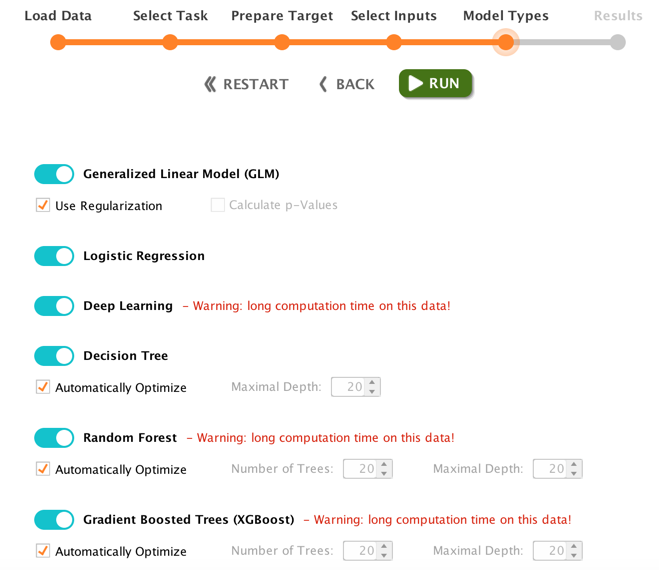
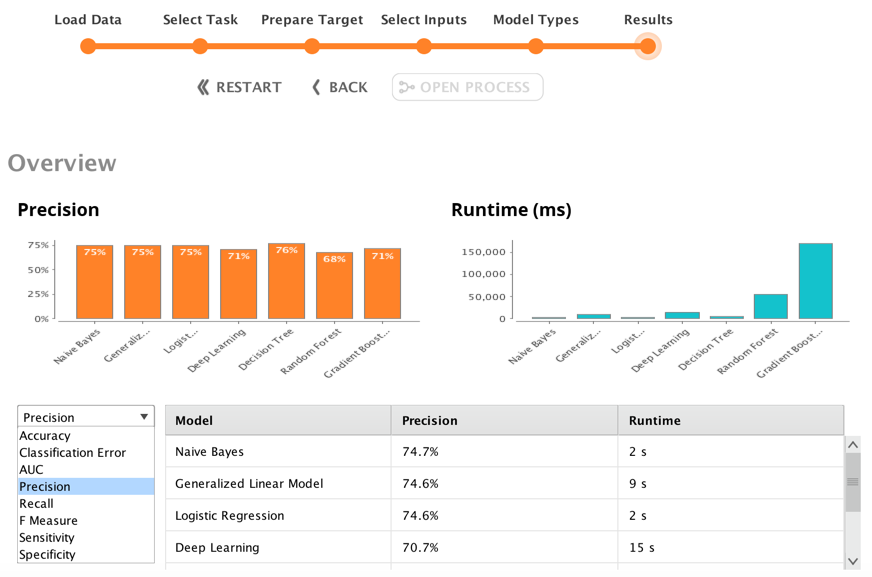
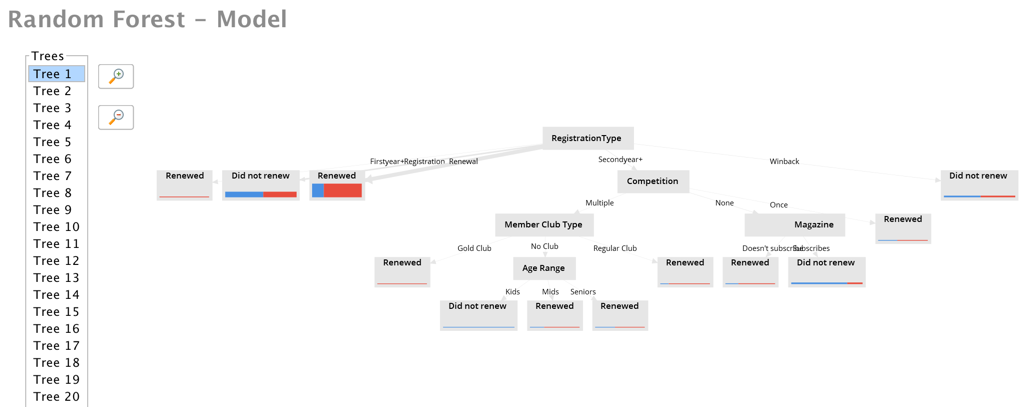
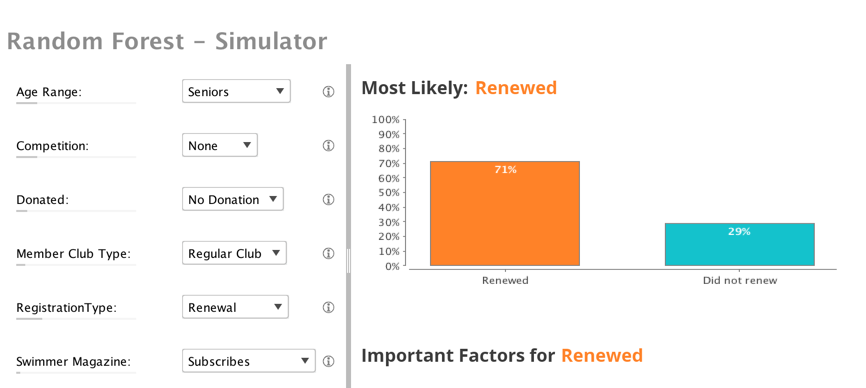
It also displayed a summary of each model, and loaded up a simulator to let me do real-time what-if scenarios. If I didn’t have access to this feature I’d be building models by hand in Python or R and it would have taken me quite a while to get to this point. I’m obviously a huge fan of the RapidMiner product, but I also want to point out the obvious. Having software build the models for you doesn’t make you a data scientist. I’m painfully aware of how little I know about the statistics behind the models at this point. I’m using this experiment, and these models as a way to jump start my understanding of machine learning and the data science behind it. I could do that with the typical training data you see in ML courses, but it’s so much more impactful when you can train on your own data, in a context that you really care about.
Validating, learning, interpreting
Now that we have a model from four years of registration data, we can use that to forecast our 2019 membership. We can take our 2018 membership data and apply it to the model. We’ve done that with January-to-August data as an intellectual exercise. Towards the end of the year, we’ll do that again, for a more formal forecast. This will reflect the first time the organization has access to a data-based projection of next year’s membership. Image what that will mean next year, when we can track membership, not in aggregate, but across tight segments of member profile, activity, etc.
Even without a full understanding of all the statistics behind the models, the information and insights from the experiment have been extremely valuable. The data has enabled us to be more precise in our conversation about membership opportunities and challenges. When we can speak about a subset of our membership, we're able to more quickly get to actionable and measurable tactics.
What's next
I mentioned above that the first pass at this model started with manual extracts of member data into flat (csv) files. We’ll be looking at modifying those data pipelines directly into the MySQL database of the membership management system. That way we’ll be able to update models on demand.

DEF tenant for PHP membership system
We’re also looking at using the model information to pass a new member profile point into Sitecore xDB. This new profile will be ‘Next year renewal likelihood’. We already have a Data Exchange Framework (DEF) job that updates xDB with member information. We’ll add onto that, with the output of the model. That will enable the membership team to build member journeys and personalize content in the context of our likelihood of retaining the member.
We’re also starting to look at other inputs that we can bring in to give more dimensions to the model. We're on the hunt for other systems that we can mine data from. Profile, goal and conversion data from xDB is probably next up.
And, last but not least, we’re starting to wrap our minds around how to turn the statistics knowledge from the model into actionable insights, and how to socialize that throughout the organization. This type of exploration is completely new to the organization, so we have to be a little careful in how we present the insights and how much detail we provide. We don’t want to overwhelm the stakeholders and come off sounding like Mr. Wizard. Rather, we want to provide digestible bites of information to our stakeholders that they can use to explore options and get actionable.
How to get started
If you're starting to think about how to apply machine learning to your customer experience design, here are a few starter thoughts.
Learn to start thinking like a scientist. See if you can start applying the scientific method to your marketing conversations. For more on that, see this companion blog post - What is context marketing.
Get to know your data. Most organizations suffer from data silos and an inability to assemble all the data bits into a single version of the truth. Going through the blending & cleansing process above will give you a better understanding of where your data lives and how it can be connected. Start by building an inventory of data sources and what type of data lives in each source.
Find/build a team within your organization. This isn't going to be a one-off project. It's going to be a discipline that you build over time. The sooner you can assemble a team, the sooner you can start a path to critical mass. It'll take some time to build the skills and get the light bulb to go off for all stakeholders. Look for likeminded individuals. Make sure to budget for training, POC work and maybe even an external project guide. And, pick a primary tool for data wrangling and model development. My opinion - take a look at RapidMiner as an option.
Pick a project & get started. Don't start with a heavy enterprise project. You're at too much risk of not getting through it. Pick a small proof of concept project that you can afford to throw away. The knowledge and project experience that you acquire should be more valuable than the output of the project. Try to pick a project that has an easy to tell story that goes along with it. That will help, as you socialize the experience throughout the organization.
If you have any questions about this project or want to talk machine learning, you can always DM me on Twitter.